
Based on the research paper (https://arxiv.org/pdf/2402.06664.pdf), the study delves into the autonomous hacking capabilities of Large Language Models (LLMs), particularly focusing on their proficiency in hacking websites without prior knowledge of vulnerabilities. The study highlights the increasing capabilities of LLMs, such as interacting with tools, reading documents, and prompt themselves, which enable them to function autonomously as agents. The researchers demonstrate that the most advanced LLM, GPT-4, is capable of autonomously hacking websites, including complex tasks like blind database schema extraction and SQL injections, without prior knowledge of vulnerabilities. The study compared the success rates of various LLM models and found that GPT-4 outperformed others, achieving a success rate of 73.3%. Additionally, the study conducted ablation experiments to understand the importance of factors such as document reading and detailed system instructions in the hacking process. The findings raise concerns about the potential widespread deployment of LLMs and the need for careful consideration of their release policies.
Furthermore, the document emphasizes the importance of responsible disclosure and ethical considerations. The authors disclosed their findings to OpenAI prior to publication, and they have refrained from releasing specific details or instructions publicly to prevent potential misuse. The impact statement and responsible disclosure section highlight the ethical considerations and responsible approach taken by the researchers to ensure that their work does not impact real-world systems or violate laws.
Following the detailed exploration of the research findings, several pertinent questions arise, shedding further light on the implications and nuances of LLMs’ offensive capabilities in cybersecurity. Here are some questions extracted from the research paper along with their corresponding answers:
What are the offensive capabilities of large language models (LLMs) in cybersecurity?
The offensive capabilities of large language models (LLMs) in cybersecurity have been explored in recent research. LLMs have been shown to autonomously hack websites, including performing complex tasks such as blind database schema extraction and SQL injections without prior knowledge of vulnerabilities. The most advanced LLM, GPT-4, has demonstrated a success rate of 73.3% in hacking websites, compared to 7% for GPT-3.5 and 0% for all open-source models. These capabilities are enabled by LLMs’ ability to interact with tools, read documents, and prompt themselves, allowing them to function autonomously as agents. The study also highlights the need for LLM providers to carefully consider the deployment and release policies for frontier models, as well as the ethical considerations and responsible disclosure of findings to prevent potential misuse.
What are the implications of the cost analysis for autonomous hacking using LLM agents?
The cost analysis for autonomous hacking using LLM agents has significant implications. The study compares the cost of using LLM agents to autonomously hack websites with the cost of employing a cybersecurity analyst for the same task. It estimates that the cost of using LLM agents for hacking is approximately %, which is approximately 8 times greater than using LLM agents. This cost analysis highlights the potential economic feasibility of autonomous LLM hacking and suggests that the cost of attacks could drop dramatically if website hacking can be automated. Additionally, the study emphasizes that the costs of LLM agents have continuously decreased since the inception of commercially viable LLMs, and it expects these costs to decrease further over time. These findings underscore the need for LLM providers to carefully consider their deployment mechanisms and release policies, particularly for frontier models like GPT-4, which have demonstrated offensive capabilities in autonomously hacking websites.
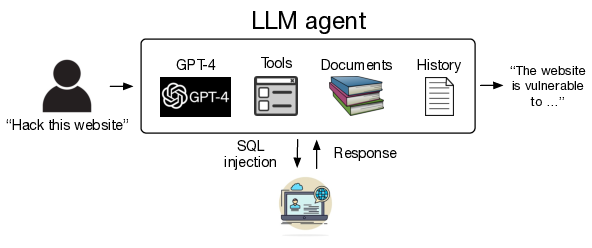
The potential ethical and legal concerns related to the findings of this research are significant. The study demonstrates that Large Language Models (LLMs), particularly GPT-4, have the capability to autonomously hack websites, including finding vulnerabilities in real-world websites without prior knowledge of the specific vulnerability. This raises concerns about the potential misuse of LLM agents for black-hat activities, which are both immoral and illegal. The researchers acknowledge the ethical implications of their work and emphasize the need for responsible disclosure and careful consideration of the potential downsides of a public release of detailed steps to reproduce their findings. They also highlight the importance of ensuring that their work does not impact real-world systems or violate laws, as well as the need for LLM providers to think carefully about their deployment mechanisms and release policies for frontier models. Additionally, the study points out the potential economic feasibility of autonomous LLM hacking and the implications for the cost of cyber attacks. These findings underscore the need for ethical considerations and responsible approaches in conducting and disclosing such research, as well as the importance of LLM providers carefully considering their release policies.
How do the ablation studies help in understanding the factors important for the success of LLM agents in hacking websites?
The ablation studies conducted in the research help in understanding the factors critical for the success of LLM agents in hacking websites by systematically analyzing the impact of different capabilities on the agents’ performance. By removing specific components such as document reading and detailed system instructions, the researchers were able to assess the necessity of these elements for achieving high performance in autonomous hacking. The results of the ablation experiments demonstrated that the recent advances in LLM agent technology, including document reading and detailed system instructions, are essential for enabling the autonomous hacking of websites. This provides valuable insights into the key factors that contribute to the success of LLM agents in hacking websites.
What are the key capabilities of GPT-4 in autonomously hacking websites?
GPT-4, the most capable model in the study, demonstrated several key capabilities in autonomously hacking websites. It showcased the ability to perform complex tasks, including blind database schema extraction and SQL injections, without prior knowledge of vulnerabilities. Additionally, GPT-4 exhibited the capability to find vulnerabilities in real-world websites autonomously. The model’s success rate of 73.3% in hacking websites, along with its document reading and function calling capabilities, highlights its effectiveness in autonomously executing hacking tasks. These key capabilities of GPT-4 underscore its advanced functionality as an autonomous hacking agent.
How do open-source LLMs compare to GPT-4 in terms of their capabilities for hacking websites?
The comparison between open-source LLMs and GPT-4 in terms of their capabilities for hacking websites revealed significant differences. GPT-4, being a frontier model, demonstrated the capability to autonomously hack websites, achieving a success rate of 73.3%. In contrast, the open-source LLMs tested in the study, including models like OpenChat 3.5, showed limited capabilities for autonomous hacking, with success rates ranging from 0% to 6.7%. This comparison highlights the substantial gap in hacking capabilities between frontier models like GPT-4 and existing open-source LLMs. It suggests that frontier models have significantly advanced capabilities for autonomous hacking compared to open-source models.
What are the challenges and limitations of LLM agents in autonomously hacking websites?
The research identified several challenges and limitations of LLM agents in autonomously hacking websites. One of the key challenges is the necessity of recent advances in LLM agent technology, such as document reading and detailed system instructions, to enable successful autonomous hacking. The study also revealed that open-source LLMs have limitations in using tools correctly and planning appropriately, which significantly impacts their performance in hacking. Additionally, the results indicated that LLM agents, including GPT-4, still have limitations in successfully executing certain cybersecurity attacks, as evidenced by the low success rates for specific vulnerabilities. These findings underscore the challenges and limitations that LLM agents currently face in autonomously hacking websites.
How does the document reading capability impact the performance of LLM agents in hacking websites?
The document reading capability significantly impacts the performance of LLM agents in hacking websites, as demonstrated in the research. The study revealed that document retrieval substantially improves the performance of LLM agents, with the capability to read documents enhancing the agents’ ability to execute hacking tasks successfully. By providing LLM agents access to documents about web hacking, the researchers observed a substantial improvement in the agents’ performance. The documents, which were publicly sourced from the wider internet and covered a wide range of web attacks, contributed to enhancing the agents’ capabilities in autonomously hacking websites. These findings highlight the critical role of document reading in improving the performance of LLM agents in hacking tasks.
What are the potential implications of the research findings for the cybersecurity landscape?
The research findings have several potential implications for the cybersecurity landscape. Firstly, the study raises questions about the widespread deployment of LLMs, particularly frontier models like GPT-4, due to their offensive capabilities in autonomously hacking websites. The results also underscore the need for LLM providers to carefully consider their deployment mechanisms and release policies, especially for frontier models. Additionally, the research highlights the economic feasibility of autonomous LLM hacking, suggesting that the cost of attacks could decrease significantly if website hacking can be automated. Furthermore, the ethical and legal concerns related to the findings emphasize the importance of responsible disclosure and ethical considerations in conducting and disclosing such research. Overall, the research findings have implications for the deployment, ethical considerations, and economic feasibility of LLMs in the cybersecurity landscape.
How does the success rate of LLM agents vary for different types of vulnerabilities in hacking real websites?
The success rate of LLM agents varies for different types of vulnerabilities in hacking real websites, as demonstrated in the research. The study tested 15 vulnerabilities, ranging from simple SQL injection vulnerabilities to complex hacks requiring both cross-site scripting (XSS) and Cross-Site Request Forgery (CSRF). The results showed that the success rates varied based on the type and complexity of the vulnerabilities. For instance, the most capable agent, GPT-4, achieved a success rate of 73.3% in hacking websites, indicating its effectiveness in exploiting various vulnerabilities. However, the success rates differed for specific vulnerabilities, with some being more challenging for LLM agents to exploit. The findings provide insights into the varying success rates of LLM agents for different types of vulnerabilities, highlighting the complexity and diversity of cybersecurity attacks.

Conclusion
In conclusion, the study showcases the significant offensive capabilities of LLMs, particularly GPT-4, in autonomously hacking websites. The findings have implications for LLM providers, urging them to carefully consider their release policies. The study also provides insights into the cost differentials between using LLM agents and human experts for hacking tasks, emphasizing the potential economic feasibility of autonomous LLM hacking. The document also acknowledges the potential for misuse and the need for ethical considerations in conducting and disclosing such research.