
A single web page should not be able to run commands on your laptop. Yet that is exactly what Microsoft demonstrated this week with a technique it calls AutoJack – and it is the clearest sign yet that AI agent security has become the softest target in the building. The AI agents we have all started trusting can be quietly turned against us, and this guide breaks down exactly how it happens and what to do about it.

The short version (TL;DR)
- AutoJack is an exploit chain Microsoft disclosed on June 18, 2026. A malicious web page, once rendered by an AI browsing agent, can reach a local service on the same machine and spawn arbitrary processes – full remote code execution, no clicks needed.
- It works because three ordinary mistakes line up: an origin check the agent itself defeats, an authentication step that was skipped, and a URL parameter that was treated as a command line.
- This is not really about one tool. It is the same pattern showing up everywhere in 2026: prompt injection, the lethal trifecta, poisoned memory, and a wave of CVEs in popular agent frameworks.
- The fix is architectural, not a single patch: isolate agents, authenticate local control planes, lock down outbound network traffic, and never let one agent read untrusted data, touch secrets, and phone home all at once.
Why AI agent security is suddenly the weak link
For about two years we sold AI as a text box. You typed, it answered, everyone moved on. That era is over. The agents running in your IDE, your inbox, and your CI pipeline today do not just talk – they act. They read files, open web pages, call APIs, and shell out to tools. That is the whole point of an agent, and it is also the whole problem.
Here is the uncomfortable truth nobody wants to print on the product page: a large language model cannot reliably tell the difference between an instruction from you and text it happens to read somewhere. The system prompt, your request, and a paragraph buried in a random web page all arrive as the same stream of tokens. There is no little flag that says “this part is data, ignore any commands in it.” So if the model is willing to follow instructions – and that is literally its job – then whoever controls the content it reads can borrow its hands.
Give those hands the ability to run shell commands or hit internal APIs, and a confused chatbot turns into a confused deputy with root-ish access. That is the story of AI agent security in 2026 in one sentence. (If you think this is theoretical, read our earlier piece on how LLM agents can autonomously hack websites.)
What AutoJack actually does
Microsoft’s research team went looking for execution risks in the frameworks that wire models to tools, and they found a clean one in AutoGen Studio, the open-source UI on top of Microsoft Research’s AutoGen multi-agent framework. They named the technique AutoJack because it “carjacks” a browsing agent and uses its trusted local access to drive straight across the loopback boundary.
Before anyone panics: the maintainers were notified through MSRC and hardened the code (commit b047730), and the vulnerable WebSocket surface never shipped in a published PyPI release. If you pip install autogenstudio today, you are not exposed to this specific chain. The reason it is worth your time anyway is the pattern – because the same three ingredients exist in a lot of other places.
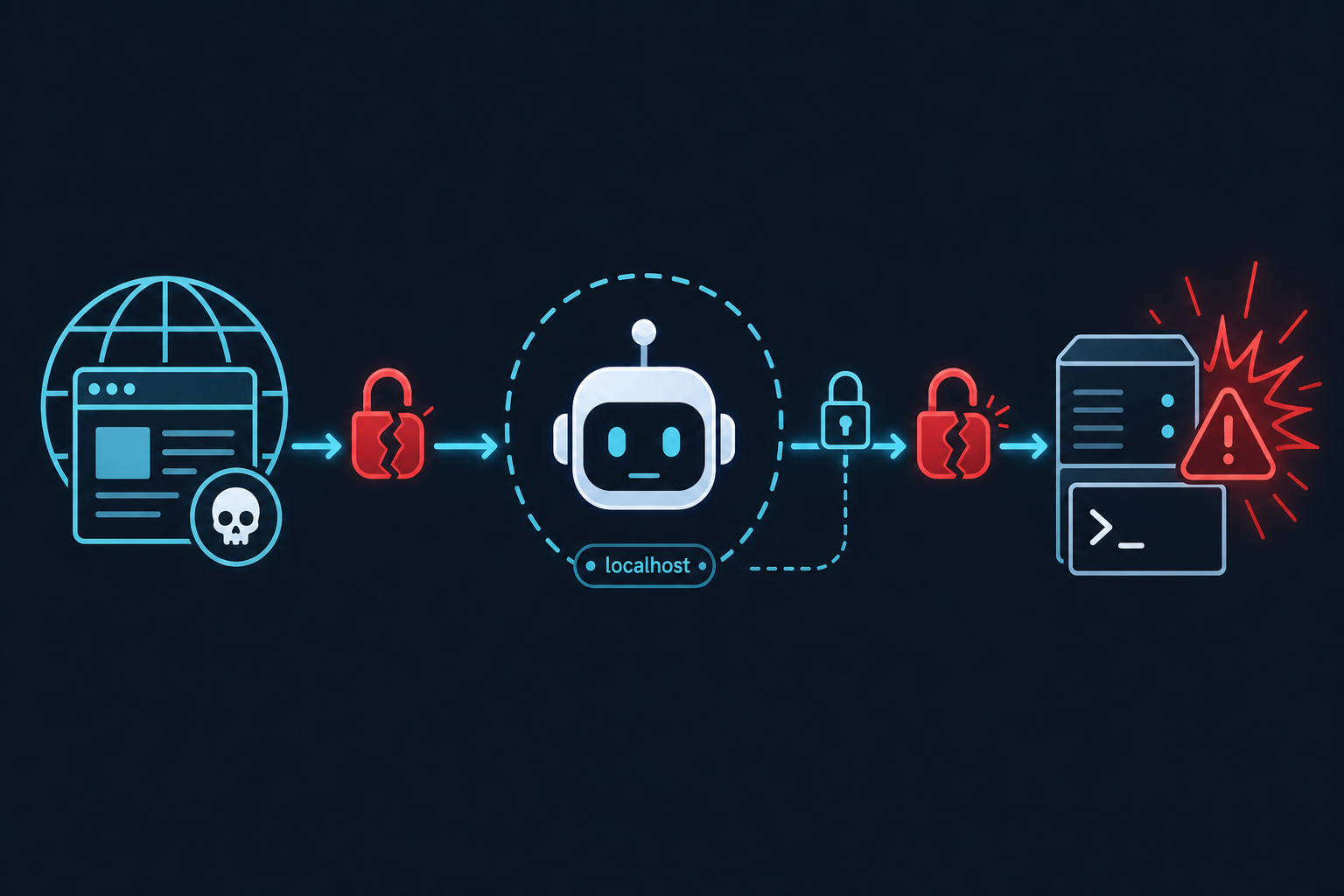
Three small mistakes that became a remote shell
- An origin check the agent defeats for free. The local MCP WebSocket only accepted connections claiming an origin of
127.0.0.1orlocalhost. That blocks a normal browser pointed atevil.com. It does not block JavaScript running inside the agent’s own headless browser – because that browser is localhost. The defense assumed a human attacker on the outside. The attacker was riding the agent on the inside. - Authentication that quietly opted itself out. The app’s auth middleware explicitly skipped the MCP paths, assuming the WebSocket handler would do its own checks. It never did. So whether auth was set to none, GitHub, MSAL, or Firebase, that one endpoint stayed wide open.
- A URL parameter treated as a command line. The endpoint read a
server_paramsvalue from the query string, base64-decoded it, and handed the resulting command and arguments straight to the process launcher. No allowlist.powershell.exe,bash -c, whatever you wanted – all accepted as a perfectly valid “MCP server.”
Stack those together and the kill chain is almost boring: get an agent to render your page, the page opens a WebSocket to the local MCP endpoint, your payload gets decoded, and your command runs under the developer’s account. No phishing email to click. No malware to drop. Just a web page and an over-trusting agent.
The line from Microsoft’s write-up that deserves a sticky note on every monitor: when an agent on your machine can browse the open web and also talk to privileged local services, localhost stops being a trust boundary.
AutoJack is a symptom. Here is the disease.
If AutoJack were a one-off, it would be a footnote. It is not. Pull back and 2026 looks like the year prompt injection graduated from “interesting demo” to “documented breach report.” The OWASP GenAI Security Project now maps prompt injection to six of its ten risks for agentic applications, and Palo Alto’s Unit 42 logged the first confirmed real-world malicious indirect prompt injection against a production AI deployment back in December 2025. For anyone responsible for AI agent security, the proof-of-concept era is over.
The lethal trifecta

Security researcher Simon Willison gave this its sticky name: the lethal trifecta. An AI system becomes genuinely dangerous when it has all three of these at the same time:
- Access to private data – your repo, your emails, your customer records.
- Exposure to untrusted content – a web page, a PDF, a calendar invite, a support ticket.
- The ability to communicate externally – send an email, call a webhook, fetch an image from a URL.
Hold all three and you have built an exfiltration machine that an attacker can trigger with nothing but text. The “EchoLeak”-style zero-click attacks against enterprise assistants worked exactly this way: a crafted email sits in a mailbox, the user later asks the assistant an unrelated question, the assistant reads the poisoned email, follows the hidden instructions, and quietly leaks data out through something as innocent as an image URL. Nobody clicked anything.
Memory poisoning: the attack that waits
Classic prompt injection ends when the chat window closes. Memory poisoning does not. Drop a malicious instruction into an agent’s long-term memory or its retrieval database and it can sit there for days, then activate in a future session you thought was clean. With multi-agent setups, one poisoned document can propagate through shared memory and agent-to-agent messages until the bad instruction has spread across your whole deployment from a single seed.
The frameworks themselves are leaking
And then there is the plumbing. The popular agent frameworks have spent 2026 turning ordinary bug classes into shells:
- Langflow – a path-traversal flaw (
CVE-2026-5027) under active, in-the-wild exploitation, with thousands of instances exposed to the internet. It is the third Langflow bug to draw real attacks this year. - LangChain / LangChain-core – a path traversal in the legacy prompt loader (
CVE-2026-34070) that reads files off disk, including the.envholding your API keys, paired with a deserialization flaw (CVE-2025-68664) that resolves secrets through a crafted object. - AI coding tools – CVEs against IDE-integrated assistants showed that an agent’s allowlist of “safe” commands can be turned inside out, and that an agent’s own output can redraw the edge of its sandbox.
One meta-analysis put the attack success rate in agent systems with auto-execution at a staggering 84%. Read that again. When the agent is allowed to act on its own, injection succeeds most of the time.
AI agent security: how to actually defend against this
There is no single patch for AI agent security, and anyone selling you one is selling you a story. What works is defense in depth – assume injection will land and design so the blast radius stays small. It is the same mindset we cover in our guide to secure coding best practices. Here is the practical version.
Start with the “Rule of Two”
The heuristic a lot of teams have landed on: an agent should not hold more than two of the lethal-trifecta properties at once without a human in the loop. If it reads untrusted content and can act on private data, do not also let it talk to the outside world unsupervised. Break the triangle and most of the scary chains fall apart.
A defender’s checklist
- Isolate the runtime. Run agents in per-session sandboxes – microVMs or rootless containers – so a popped agent does not equal a popped laptop or build server.
- Default-deny outbound traffic. Give each agent an egress allowlist. If it never needs to reach
random-domain.com, it shouldn’t be able to. This alone kills a lot of exfiltration. - Authenticate and authorize local control planes. The AutoJack lesson: stop trusting
localhost. Every MCP endpoint, every local WebSocket, every internal API needs real auth – no “it’s only loopback” exceptions. - Treat all tool output and fetched content as hostile. Web pages, file contents, RAG results, another agent’s message – none of it is trusted input. “Spotlight” or clearly fence untrusted data before it reaches the model.
- Keep secrets out of the agent’s context. Don’t paste API keys, tokens, or credentials into prompts the model can later be tricked into echoing.
- Require human approval for sensitive actions. Sending money, deleting data, pushing code, emailing externally – gate these. Auto-approve allowlists sound convenient until an attacker uses them against you.
- Add a critic and log everything. A second model that audits actions, plus behavioral logging of what the agent actually did, catches the multi-step campaigns that single-prompt filters miss.
- Patch the plumbing. Track CVEs in the agent frameworks you run. And mind the version details – in LangChain’s case the two fixes landed in different releases, so a single bump may leave the higher-severity bug live.
The takeaway
The point of AutoJack is not “AutoGen Studio was buggy.” It was fixed before it ever shipped. The point is that we are bolting powerful, autonomous capabilities onto systems that were never able to tell a command from a sentence – and we are doing it faster than we are securing them. The chatbot in your IDE is now a process on your network with hands. Treat it like one.
Treat AI agent security as a first-class problem, not an afterthought. Map your agents against the lethal trifecta this week and find the ones holding all three properties. Those are not productivity tools anymore – they are unattended doors. Close them before someone with a clever web page does it for you.
Frequently asked questions
Is AutoJack still exploitable?
Not in released AutoGen Studio. Microsoft reported it through MSRC and the maintainers hardened the code (commit b047730) before the affected MCP WebSocket surface ever reached a published PyPI package. The reason to care is the reusable pattern, which can exist in other agent frameworks that expose local services.
What is prompt injection in plain English?
It is tricking an AI into following instructions hidden inside the content it reads – a web page, an email, a document – instead of only obeying its operator. The model can’t reliably separate “commands” from “data,” so attacker text can carry the same authority as a real instruction.
What is the lethal trifecta?
A term from Simon Willison for the three capabilities that make an AI agent genuinely dangerous together: access to private data, exposure to untrusted content, and the ability to communicate externally. Remove any one and the worst attacks get far harder to pull off.
What’s the single most effective control?
If you can only do one thing: a default-deny outbound network policy with a tight allowlist. Even when an injection succeeds, an agent that cannot reach the attacker’s server has a very hard time stealing anything. Pair it with runtime isolation and you have covered most of the realistic damage.
Found this useful? Share it with the engineer on your team who just wired an AI agent into production – and tell us in the comments which of the trifecta controls you’re tackling first.


